
Les modèles d'intelligence artificielle géants comme GPT-4 sont incroyables, mais ils ont un prix : ils vivent dans le cloud, derrière des APIs coûteuses, et chacune de vos requêtes est envoyée sur les serveurs d'une entreprise. Et si vous pouviez avoir cette puissance brute, directement sur votre machine, en toute confidentialité et sans jamais payer un centime d'API ?
Aujourd'hui, nous allons faire exactement cela. Nous allons prendre l'un des modèles de langage les plus vastes et les plus performants jamais créés, DeepSeek-R1, et l'installer en local sur notre ordinateur. Comment ? Grâce à un outil qui a révolutionné l'accès aux IA open source : Ollama. Ce guide est un véritable pas-à-pas qui vous montrera non seulement comment installer et discuter avec cette IA, mais aussi comment l'intégrer dans vos propres applications Python et même construire une application web pour "discuter" avec vos propres documents PDF. Oubliez les dépendances externes, vous êtes sur le point de devenir le seul maître de votre IA.
Pourquoi exécuter une IA aussi puissante en local ?
Installer un modèle comme DeepSeek-R1 sur sa propre machine peut sembler intimidant, mais les avantages sont spectaculaires et changent la donne pour tout développeur :
- Confidentialité et Sécurité absolues : Aucune de vos données, aucune de vos conversations ne quitte votre ordinateur. C'est la solution ultime pour travailler sur des informations sensibles.
- Accès illimité et Sans interruption : Fini les limites d'utilisation (rate limits), les pannes de service ou les interruptions. Votre IA est toujours disponible.
- Performance brute : Obtenez des réponses quasi instantanées en évitant la latence des appels réseau. L'inférence se fait localement, à la vitesse de votre machine.
- Personnalisation totale : Modifiez les paramètres, peaufinez les prompts, et intégrez le modèle dans n'importe quelle application locale sans aucune restriction.
- Économies radicales : Éliminez complètement les frais d'API. Une fois le modèle téléchargé, son utilisation est gratuite et illimitée.
- Disponibilité hors ligne : Une fois le modèle sur votre disque dur, vous pouvez travailler sans connexion internet.
Mise en place de DeepSeek-R1 avec Ollama
Ollama est un outil magique qui abstrait toute la complexité. Il gère le téléchargement, la quantification (compression intelligente du modèle) et l'exécution de manière transparente.
Étape 1 : Installer Ollama
La première étape est de télécharger et d'installer Ollama depuis son site officiel. Le processus est aussi simple que pour n'importe quelle autre application.
Étape 2 : Télécharger et Lancer DeepSeek-R1
Une fois Ollama installé, ouvrez votre terminal (ou PowerShell sur Windows). Pour télécharger et lancer DeepSeek-R1, il suffit d'une seule commande.
ollama run deepseek-r1La première fois, Ollama va télécharger le modèle, ce qui peut prendre un certain temps en fonction de votre connexion internet. Une fois terminé, vous pourrez discuter avec l'IA directement dans votre terminal !
ollama run deepseek-r1:8bÉtape 3 : Lancer DeepSeek-R1 en Arrière-plan
Pour pouvoir utiliser DeepSeek-R1 dans vos propres applications, vous devez lancer le serveur Ollama en arrière-plan. Il exposera une API locale sur le port 11434.
ollama serveLaissez ce terminal ouvert. Votre IA est maintenant prête à recevoir des requêtes.
Utiliser DeepSeek-R1 en Local : Trois Méthodes
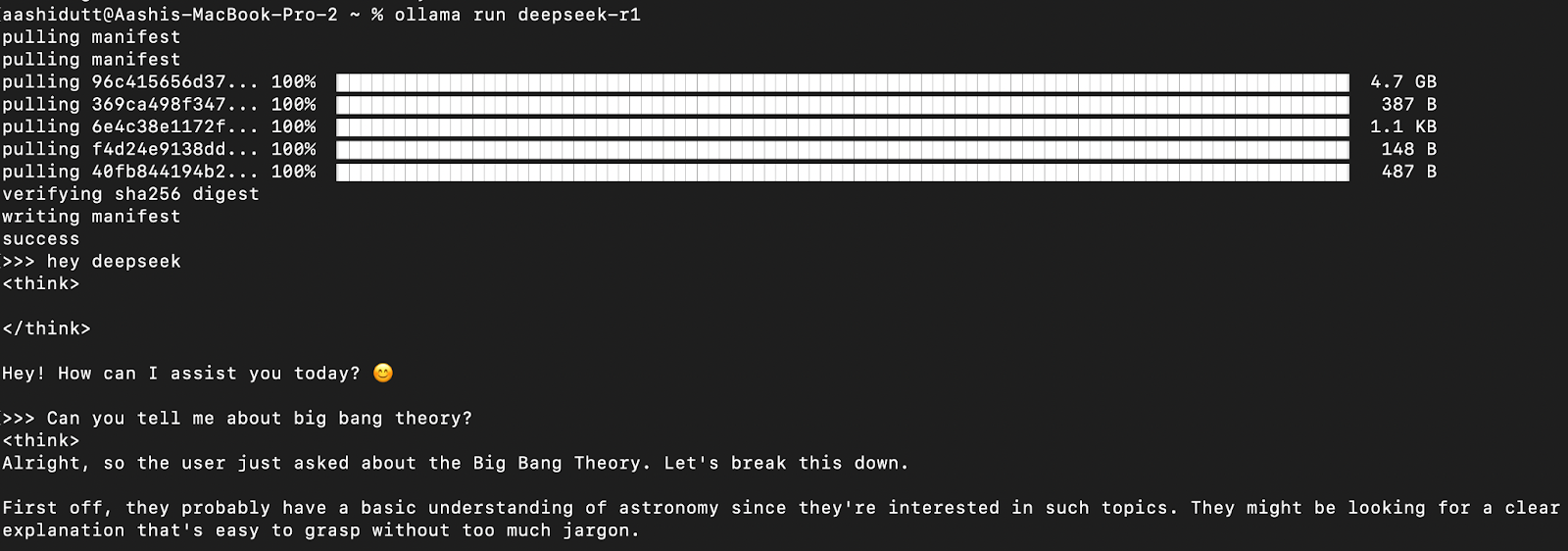
Méthode 1 : L'Interaction directe via le Terminal
C'est la manière la plus simple d'interagir. Après avoir lancé ollama run deepseek-r1, vous pouvez simplement taper vos questions et obtenir des réponses en direct.
Méthode 2 : L'accès via l'API avec curl
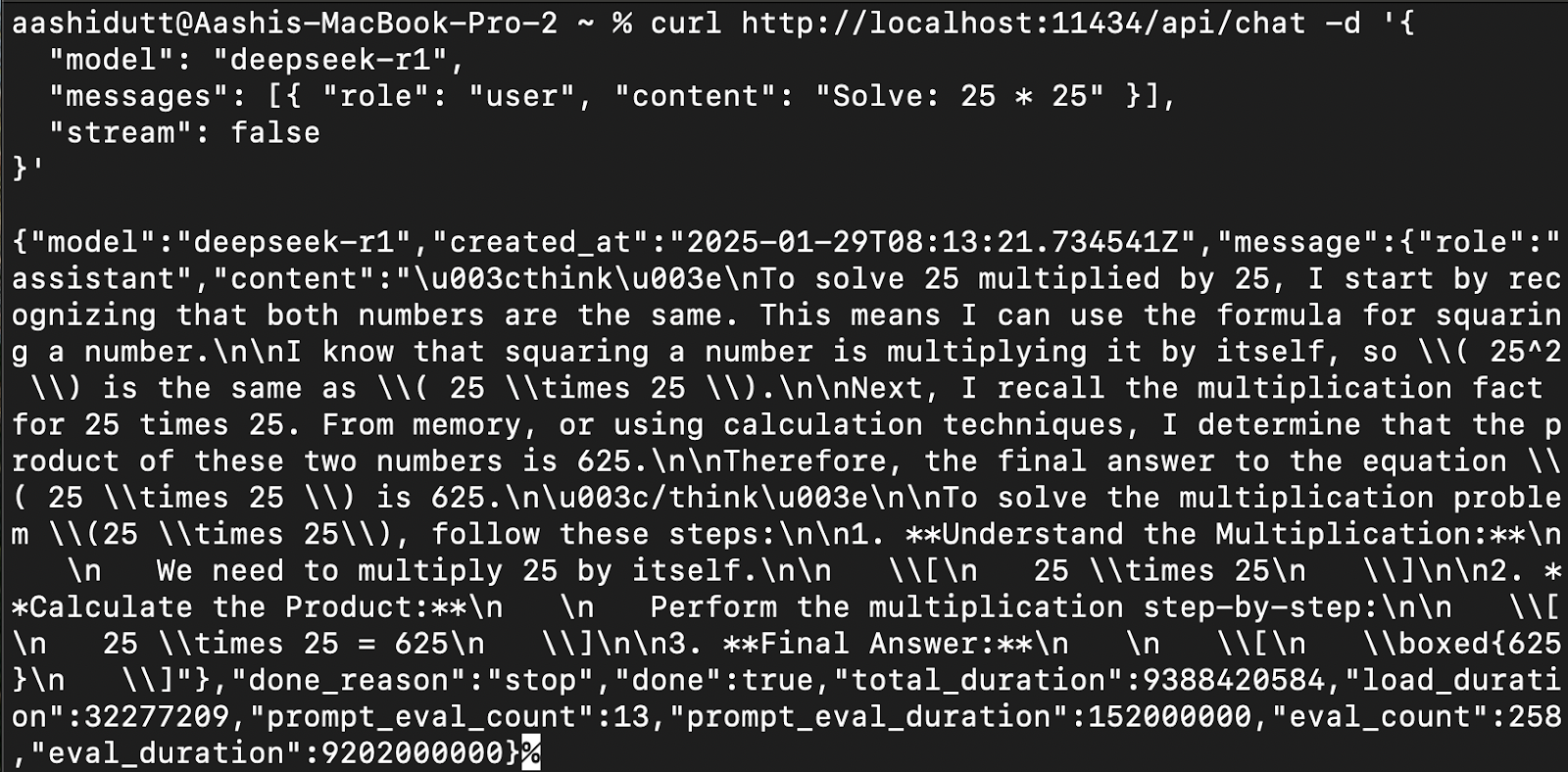
Pour intégrer DeepSeek-R1 dans d'autres applications, vous pouvez utiliser son API. La commande curl (native sur Linux/macOS, disponible sur Windows) est parfaite pour tester rapidement.
curl http://localhost:11434/api/chat -d '{
"model": "deepseek-r1",
"messages": [{ "role": "user", "content": "Calcule : 25 * 25" }],
"stream": false
}'
Méthode 3 : L'Intégration en Python (La Voie Royale)
C'est ici que la véritable puissance se révèle. Ollama fournit une bibliothèque Python officielle qui rend l'interaction incroyablement simple. D'abord, installez-la :
pip install ollamaEnsuite, utilisez ce script pour interroger le modèle :
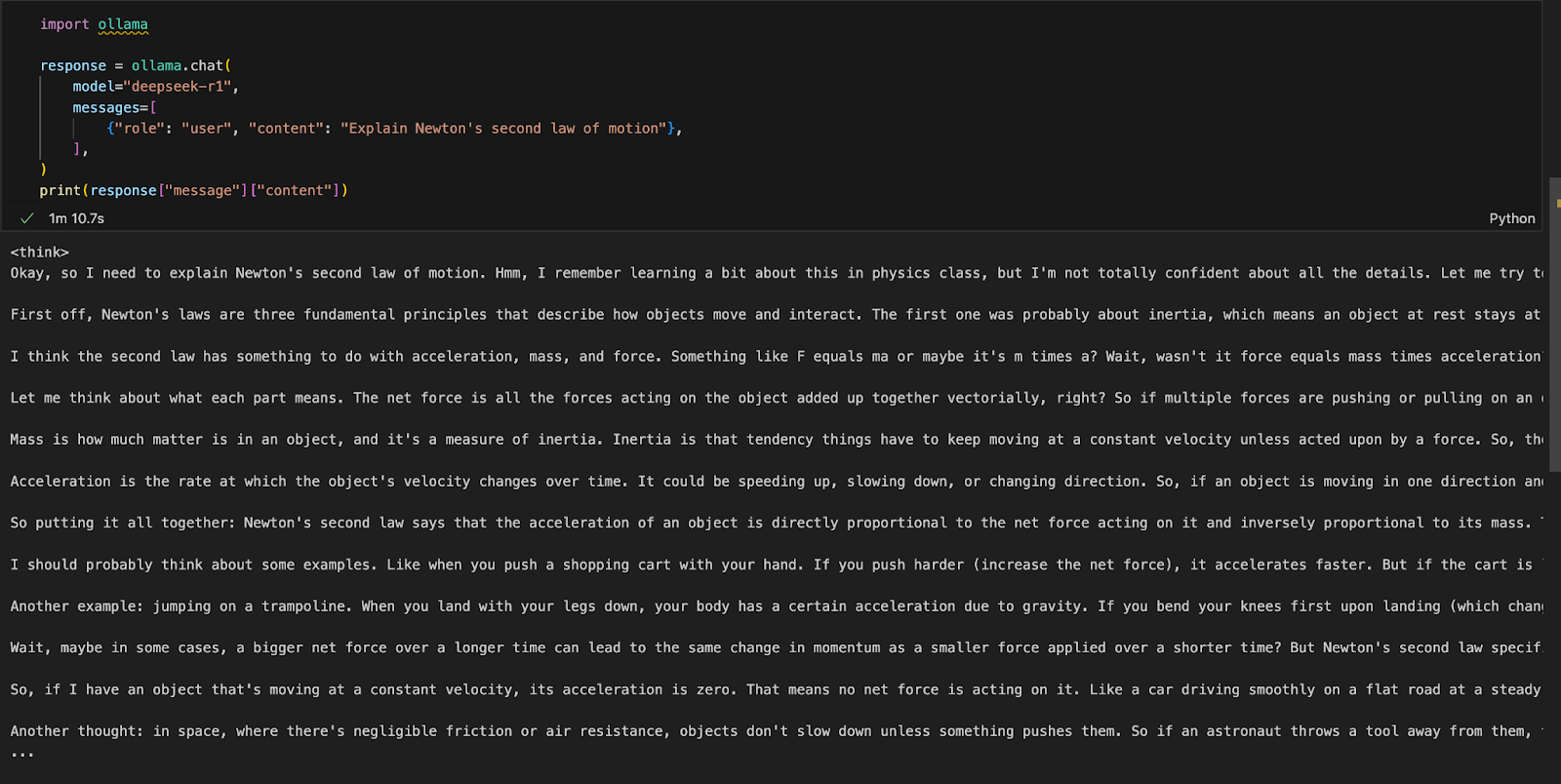
import ollama
response = ollama.chat(
model="deepseek-r1",
messages=[
{"role": "user", "content": "Explique la deuxième loi du mouvement de Newton"},
],
)
print(response["message"]["content"])
La fonction ollama.chat() envoie votre question au serveur local et vous retourne la réponse. C'est aussi simple que cela !
Projet Bonus : Construire une App Web pour discuter avec vos PDFs
Allons plus loin. Nous allons construire une petite application web avec Gradio qui vous permettra de télécharger un PDF et de poser des questions à DeepSeek-R1 sur son contenu. C'est ce qu'on appelle le RAG (Retrieval-Augmented Generation).
Étape 1 : Les Prérequis
Installez les bibliothèques nécessaires :
pip install gradio langchain chromadb PyMuPDF
pip install -U langchain-communityÉtape 2 : Le Traitement du PDF
Cette fonction va prendre un PDF, en extraire le texte, le découper en petits morceaux (`chunks`), et transformer ces morceaux en vecteurs numériques (`embeddings`) que l'IA peut comprendre.
# ... (importations nécessaires)
from langchain_community.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain_community.embeddings import OllamaEmbeddings
def process_pdf(pdf_path):
loader = PyMuPDFLoader(pdf_path)
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
chunks = text_splitter.split_documents(data)
embeddings = OllamaEmbeddings(model="deepseek-r1")
vectorstore = Chroma.from_documents(documents=chunks, embedding=embeddings)
return vectorstore.as_retriever()
Étape 3 : La Chaîne RAG
Cette fonction orchestre le processus : elle prend votre question, trouve les morceaux de texte les plus pertinents dans le PDF, et les envoie à DeepSeek-R1 avec la question pour qu'il puisse formuler une réponse basée sur le contexte.
def combine_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
def rag_chain(question, retriever):
retrieved_docs = retriever.invoke(question)
formatted_context = combine_docs(retrieved_docs)
formatted_prompt = f"Question: {question}\n\nContext: {formatted_context}"
response = ollama.chat(
model="deepseek-r1",
messages=[{"role": "user", "content": formatted_prompt}],
)
return response["message"]["content"]
Étape 4 : L'Interface Web avec Gradio
Enfin, on assemble le tout dans une interface web simple où l'utilisateur peut uploader un fichier et poser une question.
import gradio as gr
def ask_question(pdf_file, question):
if pdf_file is None:
return "Veuillez d'abord télécharger un PDF."
retriever = process_pdf(pdf_file.name)
result = rag_chain(question, retriever)
return result
interface = gr.Interface(
fn=ask_question,
inputs=[
gr.File(label="Téléchargez votre PDF"),
gr.Textbox(label="Posez une question sur le PDF"),
],
outputs="text",
title="Discutez avec votre PDF grâce à DeepSeek-R1",
description="Posez une question sur le document que vous avez téléchargé.",
)
interface.launch()
Lancez ce script Python, et une interface web s'ouvrira dans votre navigateur !
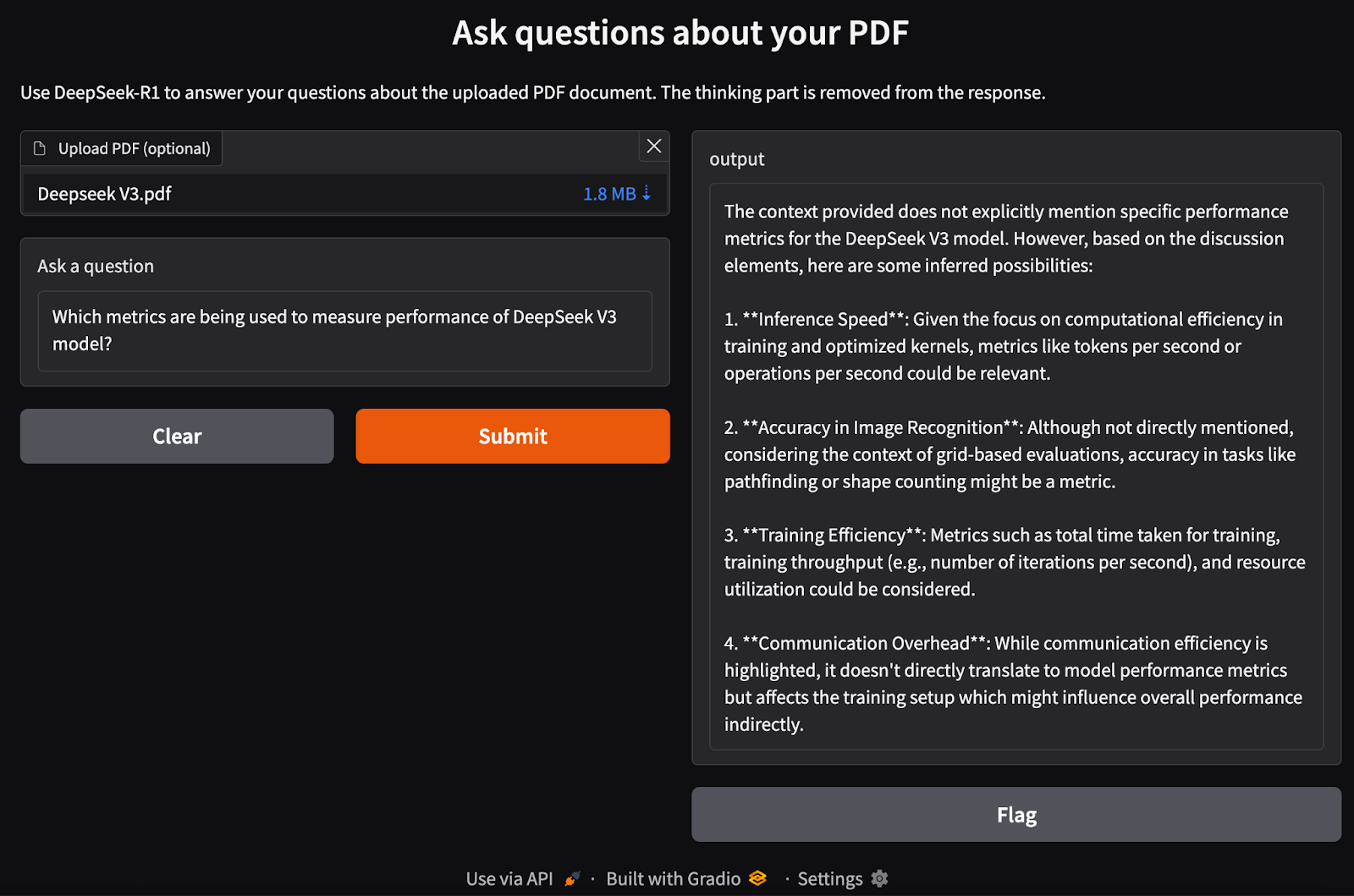
Conclusion : L'IA à Votre Service
Exécuter DeepSeek-R1 en local avec Ollama est une véritable libération. Vous avez désormais un accès plus rapide, plus privé et plus économique à une intelligence artificielle de pointe. Grâce à une installation simple, des interactions via le terminal, une API robuste et une intégration Python transparente, vous pouvez exploiter DeepSeek-R1 pour une multitude d'applications, des requêtes générales aux tâches complexes d'analyse de documents. Le futur de l'IA n'est plus dans le cloud, il est sur votre bureau.
